Stop syncing everything
Partial replication sounds easy—just sync the data your app needs, right? But choosing an approach is tricky: logical replication precisely tracks every change, complicating strong consistency, while physical replication avoids that complexity but requires syncing every change, even discarded ones. What if your app could combine the simplicity of physical replication with the efficiency of logical replication? That’s the key idea behind Graft, the open-source transactional storage engine I’m launching today. It’s designed specifically for lazy, partial replication with strong consistency, horizontal scalability, and object storage durability.
Rather watch than read?My Vancouver Systems talk explains Graft visually.
Graft is designed with the following use cases in mind:
- Offline-first & mobile apps: Simplify development and improve reliability by offloading replication and storage to Graft.
- Cross-platform sync: Share data smoothly across devices, browsers, and platforms without vendor lock-in.
- Stateless multi-writer replicas: Deploy replicas anywhere, including serverless and embedded environments.
- Any data type: Replicate databases, files, or custom formats—all with strong consistency.
I first discovered the need for Graft while building SQLSync. SQLSync is a frontend optimized database stack built on top of SQLite with a synchronization engine powered by ideas from Git and distributed systems. SQLSync makes multiplayer SQLite databases a reality, powering interactive apps that run directly in your browser.
However, SQLSync replicates the entire log of changes to every client—similar to how some databases implement physical replication. While this approach works fine on servers, it’s poorly suited to the constraints of edge and browser environments.
After shipping SQLSync, I decided to find a replication solution more suited to the edge. I needed something that could:
- Let clients sync at their own pace
- Sync only what they need
- Sync from anywhere, including the edge and offline devices
- Replicate arbitrary data1
- All while providing strong consistency guarantees.
That didn’t exist. So I built it.
#A different approach to edge replication
![]()
If you’ve ever tried to keep data in sync across clients and servers, you know it’s harder than it sounds. Most existing solutions fall into one of two camps:
- Full replication, which syncs the entire dataset to each client—not practical for constrained environments like serverless functions or web apps.
- Schema-aware diffs, like Change Data Capture (CDC) or Conflict-free Replicated Data Types (CRDTs), which track logical changes at the row or field level—but require deep application integration and don’t generalize to arbitrary data.
Graft takes a different path.
Like full replication, Graft is schema-agnostic. It doesn’t know or care what kind of data you’re storing—it just replicates bytes2. But instead of sending all the data, it behaves more like logical replication: clients receive a compact description of what’s changed since their last sync.
At the core of this model is the Volume: a sparse, ordered collection of fixed-size Pages. Clients interact with Volumes through a transactional API, reading and writing at specific Snapshots. Under the hood, Graft persists and replicates only what’s necessary—using object storage as a durable, scalable backend.
The result is a system that’s lazy, partial, edge-capable, and consistent.
Want to try the managed version of Graft?Join the waitlist to get early access: Sign up here →
Each of these properties deserves a closer look—let’s unpack them one by one.
#Lazy: Sync at your own pace
Graft is designed for the real world—where edge clients wake up occasionally, face unreliable networks, and run in short-lived, resource-constrained environments. Instead of relying on continuous replication, clients choose when to sync, and Graft makes it easy to fast forward to the latest snapshot.
That sync starts with a simple question: what changed since my last snapshot?
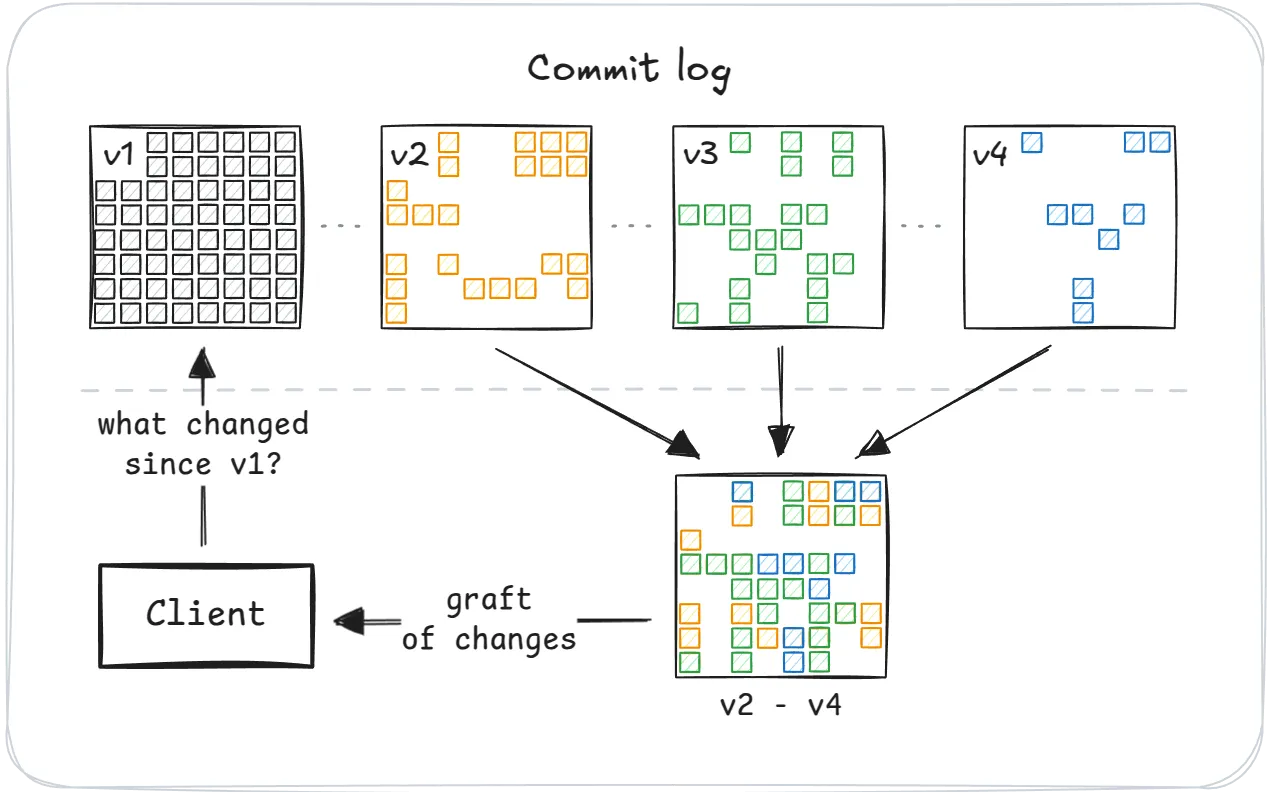
The server responds with a graft—a compact bitset of page indexes that have changed across all commits since that snapshot3. This is where the project gets its name: a graft attaches new changes to an existing snapshot—like grafting a branch onto a tree. They act as a guide, informing the
client which pages can be reused and which need to be fetched if needed.
Critically, when a client pulls a graft from the server, it doesn’t receive any actual data—only metadata about what changed. This gives the client full control over what to fetch and when, laying the foundation for partial replication.
#Partial: Sync only what’s needed
When you’re building for edge environments—browser tabs, mobile apps, serverless functions—you can’t afford to download the entire dataset just to serve a handful of queries. That’s where partial replication comes in.
After a client pulls a graft, it knows exactly what’s changed. It can use that information to determine precisely which pages are still valid and which pages need to be fetched. Instead of pulling everything, clients selectively retrieve only the pages they’ll actually use—nothing more, nothing less.

To keep things snappy, Graft supports several ways to prefetch pages:
- General-purpose prefetching: Graft includes a built-in prefetcher based on the Leap algorithm, which predicts future page accesses by identifying patterns4.
- Domain-specific prefetching: Applications can leverage domain knowledge to preemptively fetch relevant pages. For instance, if your app frequently queries a user’s profile, Graft can prefetch pages related to that profile before the data is needed.
- Proactive fetching: Clients can always fall back to pulling all changes if needed, essentially reverting to full replication. This is particularly useful for Graft workloads running on the server side.
And because Graft hosts pages directly on object storage, they’re naturally durable and scalable, creating a strong foundation for edge-native replication.
#Edge: Sync close to the action
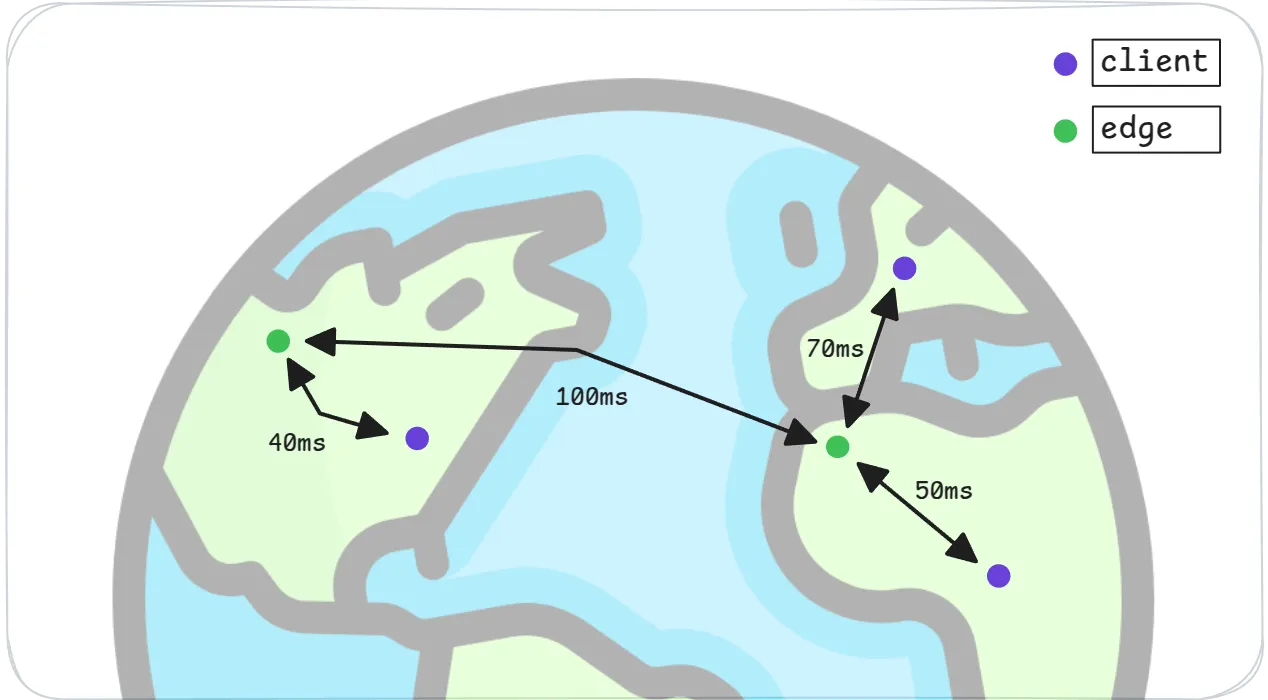
Edge replication isn’t just about choosing what data to sync—it’s about making sure that data is available where it’s actually needed. Graft does this in two key ways.
First, pages are served from object-storage through a global fleet of edge servers, allowing frequently accessed (“hot”) pages to be cached near clients. This keeps latency low and responsiveness high, no matter where in the world your users happen to be.
Second, the Graft client itself is lightweight and designed specifically to be embedded. With minimal dependencies and a tiny runtime, it integrates into constrained environments like browsers, devices, mobile apps, and serverless functions.
The result? Your data is always cached exactly where it’s most valuable—right at the edge and embedded in your application.
But caching data on the edge brings new challenges, particularly around maintaining consistency and safely handling conflicts. That’s where Graft’s robust consistency model comes in.
#Consistency: Sync safely
Strong consistency is critical—especially when syncing data between clients that might occasionally conflict. Graft addresses this by providing a clear and robust consistency model: Serializable Snapshot Isolation.5
This model gives clients isolated, consistent views of data at specific snapshots, allowing reads to proceed concurrently without interference. At the same time, it ensures that writes are strictly serialized, so there’s always a clear, globally consistent order for every transaction.
However, because Graft is designed for offline-first, lazy replication, clients sometimes attempt to commit changes based on an outdated snapshot. Accepting these commits blindly would violate strict serializability. Instead, Graft safely rejects the commit and lets the client choose how to resolve the situation. Typically, clients will:
- Reset and replay, by pulling the latest snapshot, reapplying local transactions, and trying again.
- Globally, the data remains strictly serializable.
- Locally, the client experiences Optimistic Snapshot Isolation, meaning:
- Reads always observe internally consistent snapshots.
- However, these snapshots may later be discarded if the commit is rejected.
- Merge their local state with the latest snapshot from the server. This may degrade the global consistency model to snapshot isolation.
- Fork the volume permanently, creating a new, separate volume—thus maintaining global serializability.
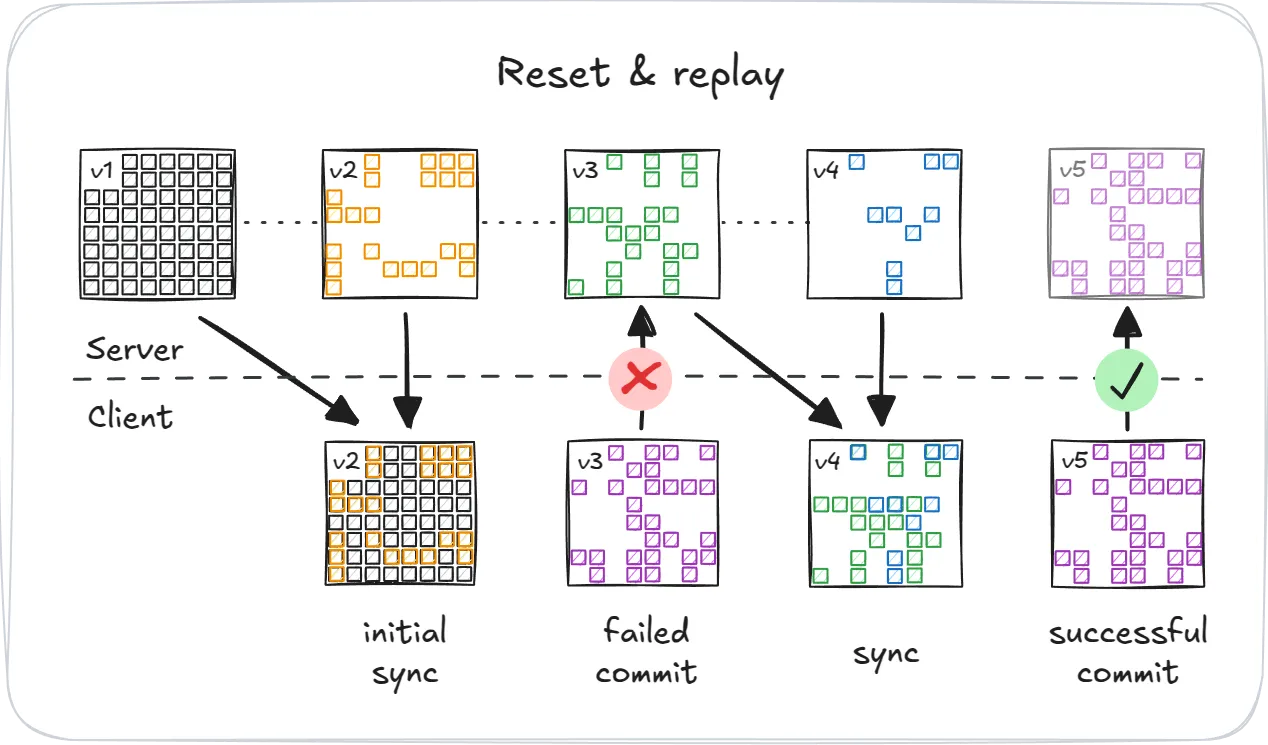
In short, Graft ensures you never have to sacrifice consistency—even when clients sync sporadically, operate offline, or collide with concurrent writes.
#What can you build with Graft?
Combining lazy syncing, partial replication, edge-friendly deployment, and strong consistency, Graft provides a robust foundation for a variety of edge-native applications. Here are just a few examples of what you can build with Graft:
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data.
Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere6.
Stateless read replicas: Due to Graft’s unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.
Replicate anything: Graft is just focused on consistent page replication. It doesn’t care about what’s inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky’s the limit with Graft.
#The Graft SQLite Extension (libgraft)
Today, libgraft is the easiest way to start using Graft. It’s a native SQLite extension that works anywhere SQLite does. It uses Graft to replicate just the parts of the database that a client actually uses, making it possible to run SQLite in resource constrained environments.
libgraft implements a SQLite virtual file system (VFS) allowing it to intercept all reads and writes to the database. It provides the same transactional and concurrency semantics as SQLite does when running in WAL mode. Using libgraft provides your application with the following benefits:
- asynchronous replication to and from object storage
- lazy partial replicas on the edge and in devices
- Serializable Snapshot Isolation
- point in time restore
If you’re interested in using libgraft, you can find the documentation here.
#How to get involved
Graft is developed openly on GitHub, and contributions from the community are very welcome. You can open issues, participate in discussions, or submit pull requests—check out our contribution guide for details.
If you’d like to chat about Graft, join the Discord or send me an email. I’d love your feedback on Graft’s approach to lazy, partial edge replication.
I’m also planning on launching a Graft Managed Service. If you’d like to join the waitlist, you can sign up here.
But wait, there’s more!Keep reading to learn about Graft’s roadmap as well as a detailed comparison between Graft and existing SQLite replication solutions.
#Appendix
#Roadmap
Graft is the result of a year of research, many iterations, and one major pivot7. But Graft is far from done. There’s a lot left to build, and the roadmap is ambitious. In no particular order, here’s what’s planned:
WebAssembly support: Supporting WebAssembly (Wasm) would allow Graft to be used in the browser. I’d like to eventually support SQLite’s official Wasm build, wa-sqlite, and sql.js.
Integrating Graft and SQLSync: Once Graft supports Wasm, integrating it with SQLSync will be straightforward. The plan is to split out SQLSync’s mutation, rebase, and query subscription layers so it can lay on top of a database using Graft replication.
More client libraries: I’d love to see native Graft-client wrappers for popular languages including Python, Javascript, Go, and Java. This would allow Graft to be used to replicate arbitrary data in those languages rather than being restricted to SQLite.8
Low-latency writes: Graft currently blocks push operations until they have been fully committed into object storage. This can be addressed in a number of ways:
- Experiment with S3 express zone
- Buffer writes in a low-latency durable consensus group sitting in front of object storage.
Garbage collection, checkpointing, and compaction: These features are needed to maximize query performance, minimize wasted space, and enable deleting data permanently. They all relate to Graft’s decision to store data directly in object storage, and batch changes together into files called segments.
Authentication and authorization: This is a fairly broad task that encompasses everything from accounts on the Graft managed service to fine-grained authorization to read/write Volumes.
Volume forking: The Graft service is already setup to perform zero-copy forks, since it can easily copy Segment references over to the new Volume. However, to perform a local fork, Graft currently needs to copy all of the pages. This could be solved by layering volumes locally and allowing reads to fall through or changing how pages are addressed locally.
Conflict handling: Graft should offer built-in conflict resolution strategies and extension points so applications can control how conflicts are handled. The initial built-in strategy will automatically merge non-overlapping transactions. While this relaxes global consistency to optimistic snapshot isolation, it can significantly boost performance in collaborative and multiplayer scenarios.
#Comparison with other SQLite replication solutions
Graft builds on ideas pioneered by many other projects, while adding its own unique contributions to the space. Here is a brief overview of the SQLite replication landscape and how Graft compares.
AttentionThe information in this section has been gathered from documentation and blog posts, and might not be perfectly accurate. Please let me know if I’ve misrepresented or misunderstood a project.
#mvSQLite
Among SQLite-based projects, mvSQLite is the closest in concept to Graft. It implements a custom VFS layer that stores SQLite pages directly in FoundationDB.
In mvSQLite, each page is stored by its content hash and referenced by (page_number, snapshot version). This structure allows readers to lazily fetch pages from FoundationDB as needed. By leveraging page-level versioning, mvSQLite supports concurrent write transactions, provided their read and write sets don’t overlap.
How Graft compares: Graft and mvSQLite share similar storage-layer designs, using page-level versioning to allow lazy, on-demand fetching and partial database views. The key difference lies in data storage location and how page changes are tracked. mvSQLite depends on FoundationDB, requiring all nodes to have direct cluster access—making it unsuitable for widely distributed edge devices and web applications. Additionally, Graft’s Splinter-based changesets are self-contained, easily distributable, and do not require direct queries against FoundationDB to determine changed page versions.
#Litestream
Litestream is a streaming backup solution that continuously replicates SQLite WAL frames to object storage. Its primary focus is async durability, point-in-time restore, and read replicas. It runs externally to your application, monitoring SQLite’s WAL through the filesystem.
How Graft compares: Unlike Litestream, Graft integrates directly into SQLite’s commit process via its custom VFS, enabling lazy, partial replication, and distributed writes. Like Litestream, Graft replicates pages to object storage and supports point-in-time restores.
#cr-sqlite
cr-sqlite is a SQLite extension which turns tables into Conflict-free Replicated Data Types (CRDTs), enabling logical, row-level replication. It offers automatic conflict resolution but requires schema awareness and application-level integration.
How Graft compares: Graft is schema-agnostic and doesn’t depend on logical CRDTs, making it compatible with arbitrary SQLite extensions and custom data structures. However, to achieve global serializability, Graft expects applications to handle conflict resolution explicitly. In contrast, cr-sqlite automatically merges changes from multiple writers, achieving causal consistency.
#Cloudflare Durable Objects with SQLite Storage 9
By combining Durable Objects with SQLite, you get a strongly consistent and highly durable database wrapped with your business logic and hosted hopefully close to your users in Cloudflare’s massive edge network. Under the hood, this solution is similar to Litestream in that it replicates the SQLite WAL to object storage and performs periodic checkpoints.
How Graft compares: Graft exposes replication as a first class citizen, and is designed to replicate efficiently to and from the edge. In comparison, SQLite in Durable Objects is focused on extending Durable Objects with the full power of SQLite.
#Cloudflare D1
Cloudflare D1 is a managed SQLite database operating similarly to traditional database services like Amazon RDS or Turso, accessed by applications via an HTTP API.
How Graft compares: Graft replicates data directly to the edge, embedding it within client applications. This decentralized replication model contrasts significantly with D1’s centralized data service.
#Turso & libSQL
Turso provides managed SQLite databases and embedded replicas via libSQL, an open-source SQLite fork. Similar to Litestream and Cloudflare Durable Objects SQL Storage, Turso replicates SQLite WAL frames to object storage and periodically checkpoints. Replicas catch up by retrieving these checkpoints and replaying the log.
How Graft compares: Graft distinguishes itself with partial replication and support for arbitrary, schema-agnostic data structures. Graft’s backend service operates directly at the page level and outsources the entire transactional lifecycle to clients.
#rqlite & dqlite
The key idea behind rqlite and dqlite is to distribute SQLite across multiple servers. This is achieved through Raft based consensus and routing SQLite operations through a network protocol to the current Raft leader.
How Graft compares: These projects are focused on increasing SQLite’s durability and availability through consensus and traditional replication. They are designed to keep a set of stateful nodes that maintain connectivity to one another in sync. Graft fundamentally differs by being a stateless system built on top of object storage, designed to replicate data to and from the edge.
#Verneuil
Verneuil focuses on asynchronously replicating SQLite snapshots to read replicas via object storage, prioritizing reliability without introducing additional failure modes. Verneuil explicitly avoids mechanisms to minimize replication latency or staleness.
How Graft compares: Graft behaves more like a multi-writer distributed database, emphasizing selective, real-time partial replication. Verneuil’s approach, meanwhile, emphasizes unidirectional asynchronous snapshot replication without guarantees around replication freshness.
#Footnotes
-
e.g. SQLite databases, JSON documents, files, or even custom binary formats ↩
-
Technically, Graft replicates pages full of bytes. This allows the metadata overhead to be small. If Graft tracked every byte, it would store more metadata than data! ↩
-
Internally, a
graftis encoded into a Splinter, a custom bitmap format based on Roaring Bitmaps but optimized for small, sparse sets of 32-bit integers. Splinter supports zero-copy reads, allowing agraftto be queried directly from memory-mapped files and network buffers. ↩ -
Using a combination of pattern detection and database indexes works surprisingly well to minimize round trips without overfetching. ↩
-
More details on Graft’s isolation model can be found in the readme. ↩
-
Please take me up on this and put Graft somewhere weird. A PlayStation 2? A Raspberry PI? Your toothbrush that’s connected to the internet for some reason. ↩
-
I got nerd-sniped by the idea of content addressable replication. I may release that work in the future if anyone wants to see a merkle tree optimized for tracking physical pages. ↩
-
Note that
libgraft, Graft’s native SQLite extension, should already work with most SQLite libraries and doesn’t require any specific language support. ↩ -
This is a mouthful to say. Hey Cloudflare, if you’re reading this, such a cool product needs a pithy name (Cloudflare D2?). ↩