Stop building databases
There comes a time in every frontend engineer’s life where we realize we need to cache data from an API. It might start off benign – storing a previous page of data for that instant back button experience, implementing a bit of undo logic, or merging some state from different API requests. But we all know what ends up happening. More feature requests show up, and soon we’re busy implementing data caches, manual indexes, optimistic mutations, and recursive cache invalidation.
These features bear a remarkable resemblance to the inner workings of databases. Indeed, in any frontend application of sufficient complexity, engineers will necessarily end up building so many data management features that they are essentially creating a domain specific database. This added complexity is duplicated in each project we work on, and takes away from spending time on delighting users and solving business problems.
So today, I’d like you to join me as we take a look at common application data patterns, and how they relate to database features. Afterwards, we will take a look at an alternative solution to these patterns - a frontend optimized database stack which allows us to focus on the application rather than micromanaging data.
Welcome to the world of accidental database programming.
#The humble cache
Our journey starts in the most humble of ways. Send an API request to the server and store it in a local variable. We might want to do this for any number of reasons, but one good example is working around declarative re-renders. Many modern web applications use declarative frameworks like React, which internally will re-render the tree many times over the course of a user’s interaction with a page. We wouldn’t want to issue an API request for each render - so we throw the data into a variable. Here is an example using React Hooks:
const Newsfeed = () => {
const [{ loading, entries, error }, setEntries] = useState({
loading: true,
entries: [],
error: null,
});
useEffect(() => {
NewsfeedAPI.getAll()
.then((entries) => setEntries({entries }))
.catch((error) => setEntries({ error }));
}, []);
// render loading, entries, and error states
return <div>...</div>;
};In this example1 we can see a basic API request cache stored using React state hooks. Once the API request completes, we will cache the result (or an error) until the component is removed and re-added to the tree.
Soon we are tempted to add more features. A common next step is to “lift the cache” into a higher layer, or out of the UI tree entirely.
One example of this is using Redux, a popular state management library for React. At its core, Redux allows developers to consolidate state and coordinate atomic changes to that state over time. However, over time, Redux has evolved into an ecosystem of tools and patterns which can be used to manage API data caching. The goal of using Redux (or similar) in this way is to centralize cache logic, coordinate refresh, and most importantly share cache results between components.
As our humble caching layer grows in complexity it starts to take on a new identity: A centralized storage system that coordinates with the rendering engine and user actions to efficiently wrangle data. We might say it’s starting to look a bit like a database…
But that’s crazy. Let’s talk about indexes instead.
#Going faster with indexes
When I started building web apps almost two decades ago, I was immediately drawn to the elegance of properly structured data. By organizing data in a certain way, the application could do less work and deliver a much better user experience. At the time, my interactions with data in the backend were abstracted through databases - databases which allowed me to think about indexes as magical fairy dust sprinkled on queries to make them go fast. It wasn’t until I joined SingleStore (formerly MemSQL) that I discovered how similar frontend data optimization was to the internals of database storage.2
One optimization we can leverage in the frontend is to store data cached from the server in an object keyed by ID. This often arises due to the structure of the underlying API. For example, in an application using a REST API, we often read some data in batch and then enrich specific objects as needed. This requires constantly merging API results into the cache which is made easier if objects are stored by ID. Let’s look at an example of this kind of cache:
const CACHE = {
"f3ac87": {
id: "f3ac87",
author: "@carlsverre",
title: "stop building databases",
description: "There comes a time in every software engineers life...",
createdAt: new Date(),
},
/*
"a281f0": { ... },
"2f9f6c": { ... },
...
*/
};
// retrieval by ID
console.log(CACHE["f3ac87"]);
// update by ID
CACHE["f3ac87"].title = "everyone is a database programmer";In the example above, we are indexing entries by ID in a simple JavaScript object. Due to this “data shape,” we have optimized for creating, reading, updating, and deleting entries by ID. However, any operation that needs to look at multiple entries, such as a filter, would require checking every entry. Let’s improve this data structure to help us quickly look up entries by date:
const truncateTime = (date) => {
const clone = new Date(date);
clone.setHours(0, 0, 0, 0);
return clone;
};
const ENTRIES_BY_DATE = Object.groupBy(
Object.values(CACHE),
(e) => truncateTime(e.createdAt),
);
// filter by date == today
console.log(ENTRIES_BY_DATE[truncateTime(new Date())]);In this second example, we create a basic index tracking the year/month/day portion of each entry’s createdAt field.3 Now our frontend has gained the ability to quickly look up entries published on a given date – at the expense of having to maintain consistency between the two data structures: CACHE and ENTRIES_BY_DATE.
Consider what happens as we start managing many of these indexes - each requiring custom logic to build, update, and query. Verifying correctness quickly becomes a burden on testing and code review. Forgetting to properly delete or update an entry in one index can lead to difficult bugs. Soon, we are spending more time building infrastructure to manage this complexity than building new application features. It’s only a matter of time before we start to realize that we are, in fact, building a database.
Caching and indexing data is not where our journey ends! Without fail, someone will realize that optimistically mutating these data structures could lead to a much snappier user experience.
#Glass half-full mutations
What are optimistic mutations anyway? Basically, the idea is to simulate the effect of a particular operation locally – before the server has had a chance to respond. By doing this, we can build user interfaces that seem to respond instantly, “eliminating” network latency. Of course, this comes at a cost - in the event that the server decides to do something other than anticipated (or there is some kind of error), the UI may need to “rollback” this change and prompt the user to fix issues. Assuming that the UI is good at predicting the server outcome (i.e. errors can be handled on the client side and logic is kept tightly in sync), optimistic mutations can be a powerful tool in a frontend engineer’s toolbox. It is also a great way to further practice our database engineering skills!
Let’s break down how optimistic mutations work, and think about the new challenges they bring to the table:
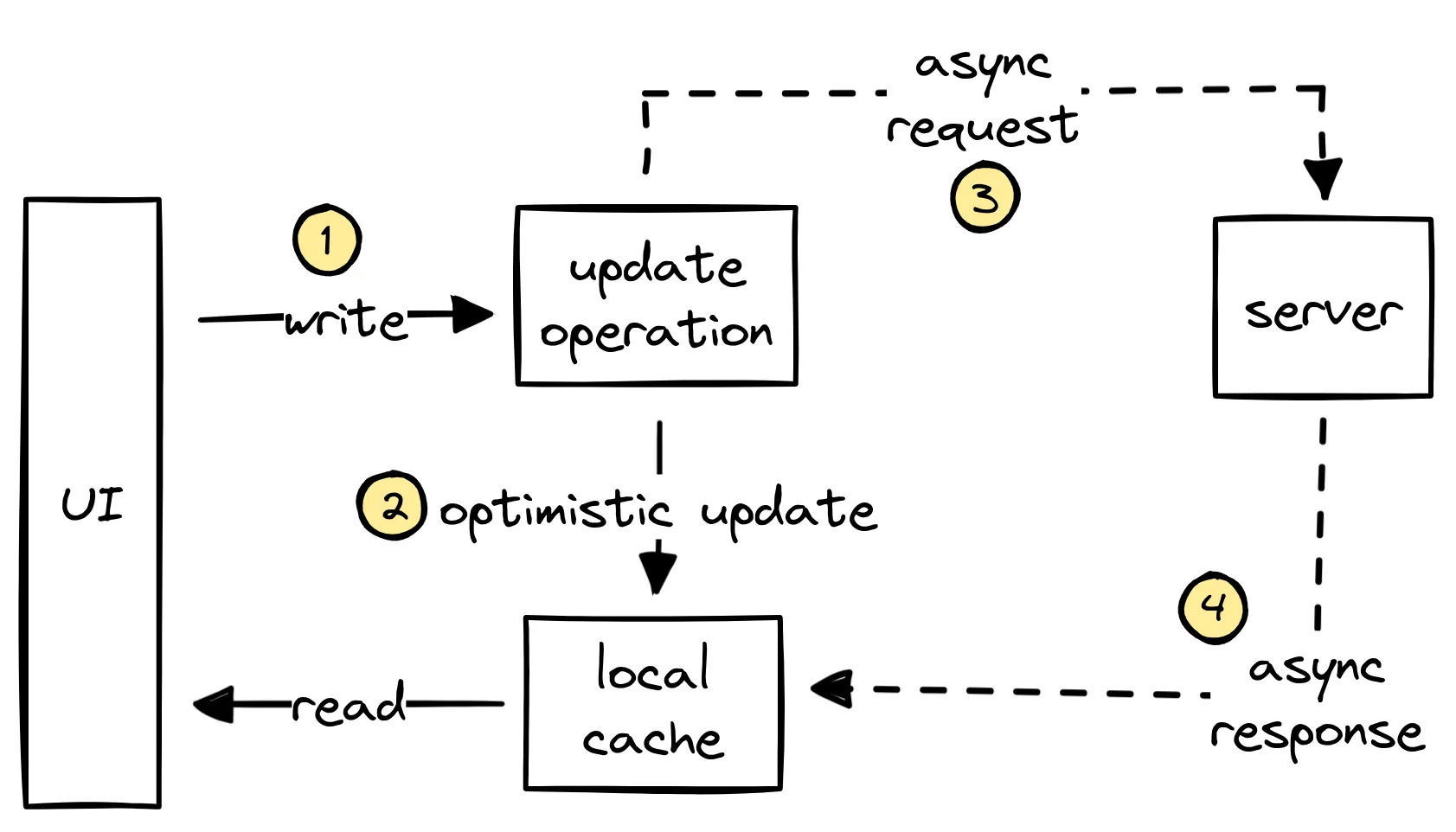
In the diagram above, we can trace the execution path of an optimistic update:
- The UI emits a write operation. In this case, the UI is trying to update some piece of data.
- This update is optimistically applied to the local cache - making the assumption that the server will end up agreeing with this decision. The UI can immediately re-render with the new state.
- Asynchronously, the update operation is sent to the server.
- Finally, the server responds with the result of the update which is merged into the local cache, overwriting the earlier optimistic update. This allows the UI to re-render (if needed), leaving the system in a (hopefully) consistent state.
Ensuring that this process maintains consistency with the server comes with a number of challenges. First, we need to duplicate logic between the client and server, so we can optimistically predict the result. Next, each in-flight mutation must be tracked in order to handle asynchronous errors or server disagreements. Finally, in order to provide the best user experience, the optimistic portion of the cache may even need to be made durable to reconcile changes across application restart. Solving each of these challenges incurs a huge tax on both developer time and correctness verification. Once again, we find ourselves micromanaging data rather than delighting customers with new, differentiating features.
But these issues pale in comparison to what I like to call: recursive cache invalidation.
#Recursive Cache invalidation
In any reasonably data intensive application, pieces of data will often show up in multiple places in the cache:
const CACHE = {
projects: {
1: { id: 1, name: "build a spaceship", progress: 0.5, numTasks: 10 },
2: { id: 2, name: "to the moon", progress: 0.0, numTasks: 10 },
// ...
},
tasks: {
1: { id: 1, project: 1, name: "finish hull design", status: "pending" },
9: { id: 9, project: 1, name: "order bolts", status: "pending" },
// ...
},
users: {
1: { id: 1, name: "Carl", assignedTasks: [1] },
2: { id: 2, name: "ChatGPT", assignedTasks: [9] },
},
};In the example above, we are caching projects, tasks, and users working on an important space mission.4 Let’s figure out what we need to do after we complete a task in order to keep the cache consistent with the server:
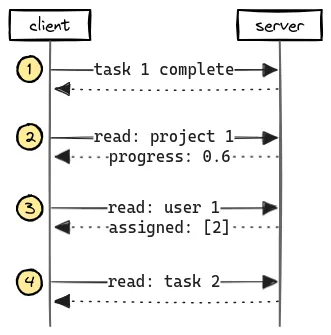
Let’s walk through the steps:
- We inform the server that the task is complete.
- Refresh the project as its progress has now changed.
- 60% complete! Now let’s check for new task assignments.
- Darn, more work to do. Let’s see what the new assignment is.
In this example, the UI has to do multiple round trips after an update to correctly invalidate every part of the cache that was potentially changed. While it’s certainly possible to build more complex APIs that reduce this into one trip,5 ultimately the result is coupling API or client logic to the underlying data model. Let’s consider two reasons why this might be bad:
First, this requires that the UI knows what part of the cache is relevant to each mutation. This can become very brittle at scale, as data relationships and aggregations may influence many parts of the local cache. Also, as the engineering team grows, these issues may even cross team boundaries, which can start to feel similar to mutable global variables in large software projects.
Second, when coupled with optimistic mutations, reproducing server logic on the client side in order to predict server changes becomes much more difficult. For example, in this case, we may want to optimistically remove task 1 from user 1 and increase the progress value by calculating a new ratio (we can use the total number of tasks). As we teach our applications how to predict these nested changes locally, our clients naturally duplicate more and more of the backend stack.
#Are we building databases?
In any frontend application of sufficient complexity, engineers will necessarily end up building so many data management features that they are essentially creating a domain specific database. This added complexity is duplicated in each project we work on and takes away from spending time on delighting users and solving business problems. My goal here was to shine a light on these patterns we have grown accustomed to and ask: where is the frontend optimized database stack we deserve?
I’m tired of waiting - so I’m tackling this problem head-on. I call it SQLSync. SQLSync is a frontend optimized database stack built on top of SQLite6 with a synchronization engine powered by ideas from Git and distributed systems. The stack is designed to integrate seamlessly with the most popular frontend frameworks like React, Vue, and Next.js. SQLSync’s goal is to handle the hardest data management problems, allowing developers to focus on what makes their application unique.
As an early example of what SQLSync can do, check out this Todo app. The entire data layer is implemented in 60 lines of Rust and a couple of SQL queries scattered across components. In exchange, SQLSync provides a durable cache, the full power of SQLite (indexes, constraints, triggers, query optimization), optimistic mutations, smart cache invalidation, and reactive queries.
Let’s briefly take a deeper look at how SQLSync approaches each of the data management problems we’ve discussed today.
SQLSync stores data locally in one or more SQLite databases. At face value, this gives us a durable cache that looks very similar to the databases we use in the backend. But it’s a durable cache with superpowers!
First off, indexes can be created easily, and are automatically kept in sync with the data. Just like on the backend, these indexes can be automatically used by the database to accelerate queries.
But it’s not just indexes! SQLite also gives us the full power of SQL which can easily express complex queries over our data, as well as triggers, foreign keys, constraints, and extensions such as full-text search.
On top of all that, SQLSync provides optimistic mutations out of the box. It does this by handling mutations in a reducer, similar to how Redux works. The reducer can be written in any language that can be compiled to WebAssembly. Using this reducer, SQLSync can execute mutations optimistically on the client, and then run them in a globally consistent order on the server. Finally, the client performs an operation similar to a Git Rebase to synchronize the client with the server.7
One advantage of SQLSync’s architecture is that it eliminates the need for recursive cache invalidation. By writing all the data mutation logic within a reducer that can be easily shared on both the client and the server, all changes made during a mutation are automatically visible. Even better, due to synchronization working like “Git Rebase”, this approach allows the server to make different changes than what happened on the client - with the guarantee that the client will always reach the same consistent outcome. This is a powerful capability that eliminates the need for developers to spend mental bandwidth on data micromanagement.
#Let’s talk!
I’m building SQLSync because I want to make client-side applications easier to build without us having to reinvent the wheel each time. If you share my vision of the future, consider starring SQLSync on Github, joining our discord, or emailing me. I’d love to hear what your perfect client-side database looks like and what you think about SQLSync’s approach to the problem.
#Prior art
The topic of using a database (or database methods) in the frontend stack is a popular topic these days. I’d like to highlight some specific articles that I found insightful and relevant.
#Riffle
In Riffle’s essay “Building data-centric apps with a reactive relational database”, the authors explore the idea of storing all application state – including UI state – in a single reactive database. Some key ideas that inspired this blog post as well as the development of SQLSync include:
- Reactive queries provide a clean mental model and align well with declarative systems like React
- Solving technical challenges in client-side application development using ideas originating in the database community
- The benefits of modeling state using a relational data model and real indexes
#Instant.db
Stepan, the author of Instant.db, wrote two fantastic blog posts on databases in the browser.
I highly recommend reading both posts, as they describe many of the same issues I mention in this post, with more of a focus on the relationship between the frontend and backend stack. Ultimately Stepan clearly describes the motivation which led to the creation of Instant.db, a graph-based successor to Firebase.
#CR-SQLite
Matt Wonlaw’s CR-SQLite is an extension to SQLite which uses conflict free replicated data types (CRDTs) and causally ordered event logs to support merging data consistently. This allows peer-to-peer applications to store and collaborate on data in SQLite without requiring a central coordinator. This project is also a fantastic example of running SQLite in the browser.
In addition, Matt is exploring related ideas like incremental computation and making SQL easier to work with via typed-sql. Overall, Matt is an inspiring builder in the space, and I recommend taking a look at what he is working on.
#Footnotes
-
This example is simplified for clarity. Instead, use battle tested API libraries instead or keep reading to learn more about frontend-friendly databases! 🙂 ↩
-
Note: indexes in databases are a lot more complex than simply storing data differently. They involve statistics collection, data versioning, transaction control, locks, and more to ensure correctness and interop with query optimization. So yeah - magical fairy dust 𖥔°݁ ˖⋆。𖥔 ↩
-
We could use many data structures to do this. This approach is pretty easy to do in JS, but not very flexible. Querying for a range of dates would require multiple accesses, for example. A potentially better data structure would be an array of entries sorted by date, combined with more complex query and update logic. ↩
-
Some people build spaceships. Some people build web apps. Some people pretend to be building spaceships while building web apps. 🚀 ↩
-
GraphQL is one approach to this problem, although it’s not perfect either ↩
-
SQLite may not only be deployed more than every other database combined, but it may be in the top five most deployed software modules of any description. ↩
-
To learn more about how SQLSync works, check out my talk at WasmCon 2023 ↩